Convolution Neural Network
- Advantages of Convolutional Neural Network
- Disadvantages of Convolutional Neural Network
The Convolutional Neural
Network (CNN) operates on a feed-forward basis, its neuron connectivity pattern
inspired by the visual cortex. This CNN deep learning architecture is prominently
used in computer vision, an artificial intelligence field focused on interpreting
visual data. In this blog the convolutional neural network explanation is done in detail.
A deep learning Convolutional Neural Network is a more advanced
version of a conventional artificial neural network that is designed
specifically to extract features from datasets that resemble grids. These
networks, also referred to as covnets, share parameters between layers. The
convolutional layer of a CNN extracts relevant characteristics from input
images by applying filters to them. To lessen the computing load, a
pooling layer also down samples the image; in the end, the fully connected layer in cnn mainly provides the final predictions. Gradient descent and backpropagation are used to determine how
the CNN model determines which filters work best.
It also generally has
three layers like Artificial Neural Networks with the same name which are the input
layer, hidden layer, and output layer.

Input layer: As the name
implies, this layer receives input from the real world. Its neuron count aligns
with the total number of features within the data (in image scenarios, this
equates to the number of pixels).
Hidden layer: After the
data passes through the input layer, it moves on to the hidden layers of the
neural network. The presence and number of these layers depend on the model
and the size of the data set. The number of neurons in each hidden layer can
vary, often exceeding the number of inputs. The learning weights and biases are
used to calculate the output of each layer by multiplying that output by a
matrix derived from the output of the previous layer. An activation function is
then applied to that result, which introduces nonlinearity in the network.
Output layer: After
processing through the hidden layers, the data is fed into a logistic function
such as sigmoid or softmax. These functions convert the results of each class
into probability scores and provide a probability estimate for each class. Then
data is produced as the output from the output layer. The output layer is the
last layer of the neural network that is used to produce the output.
The outcome generated
from this process is termed "feedforward." Subsequently, an error
calculation takes place using an error function, the error function can be a cross-entropy
or square loss error. These functions measure the network's performance or the
magnitude of error. Following this, derivatives are computed in a step called
backpropagation, primarily aimed at minimizing the loss.
Convolutional Neural Network Example
Take a look at one such case. Accurately analyzing medical photographs in the face of an increasing number of patient scans presented a significant issue for the healthcare sector. Radiology specialists were overburdened with the volume of cases, which made diagnostic delays more frequent and perhaps dangerous for patients.
Convolutional Neural Networks (CNNs) are a ground-breaking method employed by the healthcare sector to tackle this issue. These advanced artificial intelligence algorithms learned to recognize patterns suggestive of different medical disorders from large datasets of medical pictures, including X-rays, CT scans, and MRI images.
As a new patient
underwent imaging procedures, their scans were fed into the CNN machine learning model, which thoroughly
analyzed each image pixel by pixel. The CNN’s deep layers of convolutional and
pooling operations enabled it to get intricate features and nuances from the
images, far surpassing the capabilities of traditional image processing
techniques.
By using CNN radiologists
from the healthcare industry could expedite the diagnostic process while
maintaining a high level of accuracy. The CNN can flag abnormalities like
tumors, fractures, and anomalies in organs, providing the healthcare industry
and radiologist invaluable insights to guide their further process.
Convolutional Neural Network
Working
A convolutional neural
network (CNN) is an advanced version of an artificial neural network
specifically designed to extract features from grid-like matrix datasets. It
finds wide application in image or video problems where data patterns are
crucial.
CNN Architecture
The CNN has multiple
layers like the input layer, convolutional layer, polling layer, and fully
connected layers.

The first layer that
interacts with the image is the convolutional layer, which is responsible for
applying filters to the input image to extract its features. After that, the
aggregation layer samples the image to reduce the computational load. Finally,
the fully combined layer provides the final forecast. The network uses
backpropagation and gradient descent to obtain the most efficient filter.
How Convolutional Layers Works
Convolutional Neural Networks
(CNNs) share parameters across layers. Consider an image, which can be
visualized as a cuboid with length and width representing the image's
dimensions and height depicting the channels (e.g., red, green, and blue
channels in typical images).

Consider a scenario where
we extract a small segment from an image and apply a neural network, referred
to as a filter or kernel, to this segment, generating, for instance, K outputs
arranged vertically. Extending this process across the entire image involves
sliding this neural network across the image. Consequently, we obtain a
modified image, differing in width, height, and depth. Unlike the traditional
red, green, and blue channels (RGB), this image now possesses additional
channels but reduced width and height. This process is known as Convolution.
When the patch size aligns with the image size, it essentially operates as a
conventional neural network. This use of smaller patches significantly reduces
the number of weights involved.
Note: - the LeNet architecture is a pioneering convolutional neural network developed by Yann LeCun and his colleagues, that laid the foundation for modern deep learning models, that revolutionize various fields including computer vision and pattern recognition.

- Convolutional layers consist of trainable filters, often called kernels. These filters are characterized by small dimensions in both width and height and correspond to the depth of the input volume, which is typically 3 for image inputs.
- Consider an image of dimensions 34x34x3 for convolution. The size of the filter can be aXaX3, where "a" can vary as 3, 5, or 7, but must be smaller than the size of the image.
- In a forward filter, each filter moves through the entire input volume step by step. This movement is called a step, which for large images can take values like 2, 3, or 4. At each step, the network calculates the dot product between the kernel weights and the patch extracted from the input volume.
- As the filters move over the input, a 2-D output is created for each filter. These outputs are then stacked together to form an output volume with a depth equal to the number of filters used. This process allows the network to learn and adjust its filters accordingly.
Layers used to build Convolutional Neural Network
A convolutional neural
network (CNN) comprises different layers, each transforming one volume into
another using a differentiable function. Here's an overview using an example
image of dimensions 32 x 32 x 3.
Input Layer: The input
layer receives input from the external world, commonly images or image
sequences in CNNs. It holds the original image data, the image data have a
width of 32, height of 32, and depth of 3.
Convolutional Layers:
Here, the input dataset undergoes feature extraction. Kernels or learnable
filters, typically 2x2, 3x3, or 5x5 matrices, are applied to the input images.
These filters slide over the input data, performing dot products with corresponding
patches. The resulting output is termed feature maps. For instance, if there
are 12 filters in this layer, the output volume becomes 32x32x12.
Activation Layer: By
introducing nonlinearity in the network, this layer applies an element-wise
activation function to the output of the convolution layer. Popular activation
features include e.g. ReLU (max(0, x)), Tanh, and Leaky ReLU. Despite the
activation function, this layer retains its original dimensions of 32 x 32 x 12.
Pooling Layer: Periodically integrated into the CNN, this layer aims to reduce data volume size for faster computation, less memory usage, and overfitting prevention. Common types are max pooling and average pooling. For instance, using 2x2 filters and a stride of 2 in max pooling would yield an output volume of 16x16x12.

Flattening: After the convolution
and pooling of layers, the resulting feature maps are smoothed into a
one-dimensional vector. This reformulation allows them to be sent to a fully
connected layer suitable for solving categorical or regression problems.
Fully Connected Layers: This
layer, located immediately before the output layer, receives input from the
previous layer and performs computations for the final classification or
regression task.
Output layer: The output
of the fully connected layers is fed into a logistic function that effectively
transforms the output of each class into an equivalent probability score
indicating its classification probability, such as with sigmoid or softmax
functions.
Advantages of Convolutional
Neural Network
- Feature Learning: CNNs automatically learn hierarchical representations of features from input data. Convolutional layers work to extract low-level features like edges and textures, on the other hand, deeper layers learn high-level representations like shapes and patterns. This hierarchical feature extraction reduces the need for manual feature engineering.
- Spatial Hierarchies: CNNs preserve the spatial relationships between pixels in images due to their convolutional and pooling operations. This spatial awareness enables them to capture local patterns regardless of their location in the image.
- Parameter Sharing: By using shared weights via convolutional kernels, CNNs able to significantly reduce the number of trainable parameters, making them more efficient in terms of memory and computation. This sharing also allows them to generalize better to new, unseen data.
- Translation invariance: In CNN we have a translational invariance, it can detect patterns from images regardless of their location. It helps CNN in image translation, rotation and distortions.
- Pooling Layers: Through pooling layers (e.g., max pooling), CNNs mainly down-sample the feature maps, which reduces computational requirements while retaining essential information. This down-sampling aids in learning more robust and invariant features.
- Versatility and transfer learning: already trained CNN models on the big dataset can used in other tasks for feature extraction, therefore we use transfer learning in CNN for various aspects.
- State-of-the-Art Performance: image classification using CNN is one of the most used aspects of CNN architecture that it has achieved. Object detection, semantic segmentation, and other tasks also take benefits from CNN and shows their effectiveness in handling complex visual recognition challenges.
- Scalability: CNNs can handle large-scale and high-resolution images which make them very useful in real-world applications in which we need to analyze large or high-dimensional data.
Disadvantages of Convolutional
Neural Network
- Computational Complexity: CNN needs more computational power compared to the traditional approach the computation power increases as CNN becomes deeper, making CNN more computationally expensive and also resource-intensive. This complexity can hinder their deployment in resource-constrained environments.
- Large Data Requirements: CNNs generally require large labeled datasets for effective training. Inadequate data might lead to overfitting or less optimal performance of the model.
- updating & Hyperparameters: Choosing and tweaking suitable hyperparameters (such as kernel size and number of layers) is a challenging and time-consuming process in creating the best CNN architecture.
- Limitated interpretability: It is challenging to understand how and why CNNs create particular predictions because of their complex architecture. This interpretability issue might be problematic in an area where responsibility and openness are required.
- Overfitting: Using smaller datasets in particular, deeper CNN architectures with more parameters are more likely to overfit. Many times, regularization methods are required to avoid overfitting.
- Technical Specifications: Instruction Complex CNN models sometimes require specialized hardware (such as GPUs or TPUs), which not all users or applications may have easy access to or capacity for.
- Preprocessing and Augmenting of Data: To guarantee consistency, cleanliness, and sufficiency, data preparation for CNNs frequently requires substantial preprocessing and augmentation. Complex and time-consuming might be this procedure.
- Lack of Rotation and Scale Invariance: while CNNs possess translation invariance, they may not inherently generalize well to rotations or scale variations in images without additional techniques or augmentation.
Summary
At the forefront of
modern computer vision, Convolutional Neural Networks (CNN) provide a sophisticated
architecture designed to extract complex patterns from visual data. Basic
components such as convolution and pooling layers play a key role in
hierarchical feature extraction. Convolutional layers apply filters to input
images and detect various visual features such as edges and textures. These
features are then compressed by joining the layers, preserving important
information while reducing computational complexity. These networks use
hierarchical learning and progress through layers to identify increasingly
complex patterns by combining lower-level features. The inclusion of non-linear
activation functions such as Rectified Linear Units (ReLU) adds flexibility and
complexity to the learning of the network, allowing it to model complex relationships
within images.
The prowess of CNNs extends across a spectrum of image-related tasks, from CNN model for image classification and object detection to semantic segmentation. Despite their remarkable performance, CNNs demand substantial computational resources and extensive labeled datasets for training. Moreover, interpreting, CNNs stand as a pillar in reshaping machine understanding of visual information, propelling advancements in artificial intelligence, and bolstering applications in diverse domains, from healthcare and autonomous vehicles to robotics and beyond. Graph convolutional network have emerged as a powerful extension of convolutional neural networks, that offer advanced capabilities for processing graph-structured data.
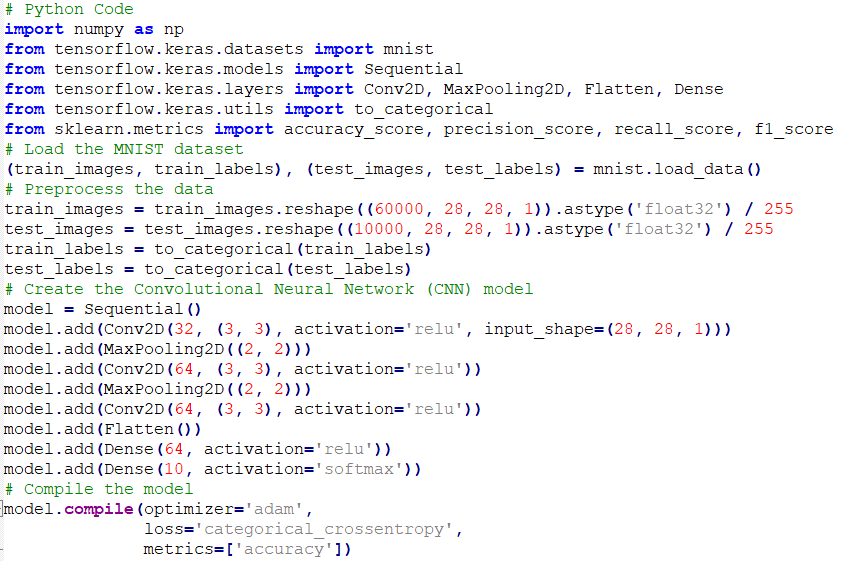
Python Code





No comments:
Post a Comment